
Metodología BIM en el reconocimiento de imágenes mediante inteligencia artificial por José Miguel Luna

José Miguel Luna
Responsable de Desarrollo del Grupo Enerdex
Caso de creación de un dataset de imágenes para el entrenamiento de redes neuronales convolucionales mediante metodología BIM.
¿Qué es la inteligencia artificial?
Una definición clásica dice que la Inteligencia Artificial (IA) es una subdisciplina del campo de la informática que busca la creación de máquinas que puedan imitar comportamientos inteligentes. Más interesante tal vez sea, por la reflexión que conlleva, la que dice que la (IA) busca la creación de máquinas que tengan comportamientos tales, que si los hiciera un ser humano se considerarían inteligentes, todo ello, entendiendo inteligencia como la capacidad de comprender y aprender, precisamente las habilidades que nos han hecho destacar como especie en el proceso evolutivo de este planeta.
Así enunciada, la inteligencia artificial ha ido desarrollando, especialmente en las últimas décadas, diversas áreas o disciplinas como: la robótica, el tratamiento de imágenes, el procesamiento del lenguaje natural o (NLP), el tratamiento de sonidos o el aprendizaje automático o Learning machine, entre otras. Ésta última, el learning machine, definido como la rama del campo de la inteligencia artificial que busca dotar a las máquinas de capacidad de aprendizaje, esto es, capacidad de adquirir conocimiento a partir de la experiencia, ha ganado tal relevancia en los últimos años, que se ha convertido en un componente esencial en la evolución del resto de las otras disciplinas.
¿Cómo aprenden las máquinas?
Las máquinas “aprenden” mediante la aplicación de algoritmos matemáticos como los modelos de regresión, clasificación, clusterización, etc. Pero si este campo ha evolucionado de forma vertiginosa en los últimos años ha sido gracias a uno de ellos especialmente, las redes neuronales, que ha dado lugar al llamado aprendizaje profundo o Deep learning.
Una red neuronal es un algoritmo compuesto por funciones matemáticas, relativamente simples, llamadas “neuronas” por su analogía con el campo de la biología. Así definida, estará compuesta por unas variables de entrada, unos valores llamados “pesos” que darán mayor o menor influencia a cada una de esas variables de entrada, una variable llamada bias o sesgo, y una función, la función de activación, que conferirá carácter no lineal a la salida de la neurona. (Figura 1)
Las neuronas, conceptualmente, se organizan en capas con un número variables de ellas por cada capa. Cada neurona de una capa se conecta con todas las neuronas de la siguiente, formando una estructura mallada compleja. Se distinguen tres tipos de capas. La capa de entrada, compuesta por las neuronas que tomarán valores del exterior del algoritmo. La capa de salida, que dará el resultado de la red neuronal. Finalmente, un número variable de capas compuestas por un número igualmente variable de neuronas conectadas por un extremo a la capa de entrada y por el otro a la de salida llamadas capas ocultas. (Figura 1)
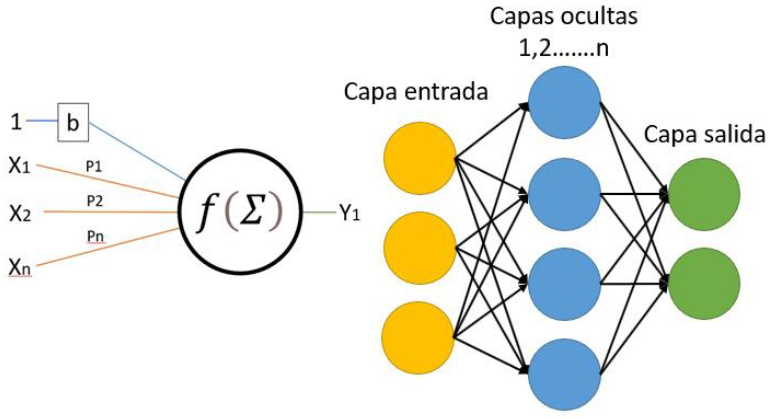
Las entradas a una red neuronal son valores numéricos obtenidos de fotos, videos, textos, sonidos, datos en general, y las salidas serán igualmente datos que se podrán convertir en fotos, textos, números o sonidos entre otros. Finalmente, una vez establecida la estructura del algoritmo, capas y neuronas, es necesario “entrenarla”, es decir, ir ajustando progresivamente el valor de los “pesos” mencionados para conseguir de ella los resultados esperados.
Los grandes avances de la inteligencia artificial que nos permiten, por ejemplo, comunicarnos con las máquinas de forma coloquial o la visión artificial provienen, fundamentalmente, del campo del learning machine y del desarrollo de nuevas teorías en la construcción de redes neuronales. En el campo de la visión artificial, las redes neuronales convolucionales (CNN) son la base conceptual de las redes neuronales orientadas al reconocimiento de imágenes. ALEXNET, R-CNN, RETINA-NET o YOLO (You only estilo once) son ejemplo de ellas.
Entrenamiento de una red neuronal
El entrenamiento de una red neuronal, como hemos dicho, es un proceso esencial para conseguir el resultado esperado de ella. Durante el entrenamiento se van “creando”, “modificando” o “destruyendo” virtualmente conexiones entre las neuronas que forman la red, proceso muy parecido al de los seres vivos. Existen varios tipos de entrenamiento en función del tipo de red neuronal que se trate: supervisado, no supervisado, por refuerzo, etc. En este
artículo nos centraremos en el tipo de entrenamiento supervisado, es decir, aquel que enseña a la red la relación entre las variables de entrada y salida. Esto se consigue mediante la iteración sobre el algoritmo de multitud de ejemplos, previamente tratados, que llamaremos dataset de entrenamiento y verificación (TraVe).
Para el reconocimiento de imágenes mediante un entrenamiento supervisado tendremos que generar un dataset compuesto, por una parte, por imágenes que contengan aquello que queramos sea reconocido por el algoritmo (personas, objetos, animales, posiciones, etc.), y de otra, por un archivo de metadatos: coordenadas delimitadoras del objeto (bounding box), silueteado, máscaras, etc. que contiene información procesable por los algoritmos para poder identificar los elementos a reconocer. (Figura 2)

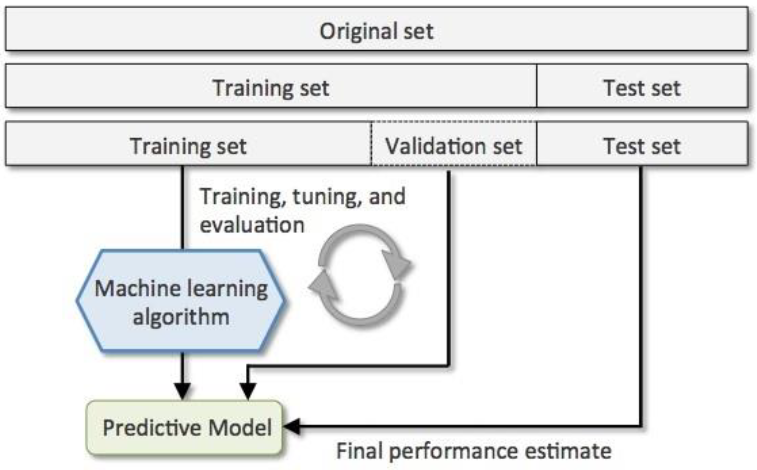
En la construcción de un dataset es importante la elección de los datos para las fases de entrenamiento, validación y prueba para evitar problemas de sesgo, overfitting o underfitting, es decir, sobreajuste o subajuste, de tal manera que el modelo solo responde bien a los datos con los que fue entrenado, fallando o disminuyendo su capacidad de predicción cuando éstos se generalizan. (Figura 3)
Actualmente están disponibles innumerables dataset para entrenamiento supervisado con archivos y contenidos de todo tipo: estadísticas, imágenes con objetos de todo tipo, videos, sonidos, textos, etc. al igual que están disponibles algoritmos de código libre, incluso ya pre-entrenados para distintas funciones. YOLO, el algoritmo de identificación de imágenes antes mencionado, cuenta con un pre-entrenamiento sobre la base de un dataset de más de 500.000 imágenes. En otros campos, como el reconocimiento del lenguaje natural (NPL), tenemos a BERT, un algoritmo desarrollado por Google para refinar las búsquedas de su buscador, que fue entrenado con 3.300 millones de palabras procedentes de Wikipedia y de Google Books.
BIM e inteligencia artificial
BIM e inteligencia artificial ya están compartiendo de la mano diversos proyectos como por ejemplo el diseño generativo, pero en este caso vamos a proponer un proyecto más cercano relacionado con la fase del entrenamiento de una red neuronal convolucional. Aunque hay muchos dataset disponibles con gran cantidad de contenidos, pocos de ellos están relacionados con el sector industrial, instalaciones, u otros campos técnicos que permitan entrenar una (CNN) específicamente para este fin. Es aquí donde la metodología BIM entra en este caso. BIM puede generar imágenes digitales de cualquier tipo de instalación con la que entrenar a una (CNN). Supongamos un espacio, un aula en este caso, en la que queramos contar el número de personas presentes, distancia, etc. a partir de su huella termográfica mediante un sensor IR que se situará siempre en una posición fija y determinada. (Importante: Este procedimiento se propone para evitar el diseño de equipos que capten imágenes identificables de personas y esto suponga problemas ligados a los derechos de privacidad o imagen, no para medir temperaturas).
Generar un número suficiente de imágenes de este tipo para conseguir un entrenamiento consistente, implicaría huellas termográficas en distintas posiciones, número, etc. todas ellas etiquetadas adecuadamente.
Para ello, se partió de una imagen termográfica real de un aula captada por el dispositivo antes mencionado en la que se determinaron zonas de color diferenciadas en función de la huella termográfica de los objetos presentes: personas, pupitres, suelo y paredes, identificadas mediante una escala de color con sus correspondientes valores RGB (Figura 4).

Mediante BIM se simuló, con la vista de cámara en la misma posición y profundidad de campo que el dispositivo real, el mismo recinto y sus objetos, incluidos unos “dummies termográficos”, a los que se les aplicó materiales consistentes con sus características IR reales (Figura 5 y 5bis) dando como resultado unas imágenes termográficas simuladas de los espacios considerados. (Figura 6 y 6bis).


Posteriormente se etiquetó estas imágenes mediante un archivo complementario en formato (.xlm) estableciendo como metadatos las coordenadas de las cajas delimitadoras (bounding box) de los objetos a identificar y una categoría, personas en este caso (Figura 7)



Resumen
Esta aplicación de BIM e inteligencia artificial orientada originalmente al diseño de dispositivos IoT de bajo coste para aforamiento de espacios interiores, podría ser utilizada para el reconocimiento de objetos de cualquier tipo de instalación: PCI, climatización, industrial, etc. sin necesidad de contar con sus imágenes reales, todo ello para su uso en aplicaciones como por ejemplo, supervisión, vigilancia o mantenimiento robotizado de instalaciones, de inventario, etc., todas ellas generadas a partir de un modelo BIM disponible o bien uno hecho ex profeso para este propósito que luego podría ser utilizado para otros fines como el facility manager o el property manager.

